Training and Deploying a Multi-Label Image Classifier using PyTorch, Flask, ReactJS and Firebase data storage Part 1: Multi-Label Image Classification using PyTorch

This is the first blog from the series of blogs based on building deep learning models and taking them to production.
The code included in the blog post can be found here.
1. Introduction to Multi-Label Image Classification and the Image dataset
Let’s define Multi-Label classification, we can consider this problem of multi-label classification as Multiple Binary Class Classification. In layman’s terms, supposedly, there are 20 different class labels in a dataset of images. Any image in the dataset might belong to some classes and those classes depicted by an image can be marked as 1 and the remaining classes can be marked as 0. Now to solve this classification problem we can consider each label as a different class and can perform binary classification on each such class and thus train a Multi-Label Classifier.
The image dataset used for this blog tutorial is the Large-scale CelebFaces Attributes (CelebA) Dataset. In this dataset there are 200K images with 40 different class labels and every image has different background clutter and there are whole lot of different variations which makes it tough for a model to efficiently classify every class label.
2. Coding a Multi-Label Classifier in PyTorch
2.1. Adding the dataset to Google Colab
- For building a Multi-Label classifier we will be using the Align and Cropped Images dataset available on the website. Here, we are specifically using Google’s Colab notebooks to make it easy to access the data and start with building the model quickly. The dataset is available on Google Drive and using the link we can add the dataset to our drive using Share-it-with-me.
- After getting the dataset on your drive we can open the a Colab notebook from our drive (if you can’t find Google Colaboratory inside the Create NEW of your drive choose connect more apps and search colab) and set the runtime type to GPU.
- To access the data we need to mount the drive and extract the compressed images folder to our drive instance and from here we start with our code. Happy Coding…
from google.colab import drivedrive.mount('/content/drive')
- Extracting Image Data
import osimport zipfileimport pandas as pdimport numpy as npimg_zip_path = '/content/drive/My Drive/CelebA/Img/img_align_celeba.zip'zip_ref = zipfile.ZipFile(img_zip_path, 'r')zip_ref.extractall()zip_ref.close()
- Getting Image Annotations
labels_path = '/content/drive/My Drive/CelebA/Anno/list_attr_celeba.txt'labels_df = pd.read_csv(labels_path)labels_df.head()
2.2. Training and Validation Data
The data as mentioned earlier has 40 different labels for every image, but when we convert the .txt file to a dataframe we have only one column as we can check it using the following line of code:
len(labels_df.columns)
And if you checked the head of the data frame it had -1 and 1 for a class present or absent in the image/ if an image belongs to that particular class.
Now we will replace this -1 with 0 and also get all the 40 columns in the dataframe to make it easy for our Dataset generator to generate batches and pass it on to the dataloader.
label_dict = {}for i in range(1, len(labels_df)):label_dict[labels_df['202599'][i].split()[0]] = [x for x in labels_df['202599'][i].split()[1:]]label_df = pd.DataFrame(label_dict).T## uncomment to check the output of the newly created dataframe.# label_df.head()label_df.replace(['-1'], ['0'], inplace = True)
Now we will create a train and a valid directory and divide our images and labels among them randomly into 70:30 ratio.
from glob import glob
from tqdm import tqdmfiles = glob('img_align_celeba/*.jpg')
shuffle = np.random.permutation(len(files))for i in ['train', 'valid']:
os.mkdir(os.path.join('/tmp/', i))
valid_dict = {}
valid_file_names = []
for i in tqdm(shuffle[:60780]):
file_name = files[i].split('/')[-1]
labels = np.array(label_df[label_df.index==file_name])
valid_dict[file_name] = labels
valid_file_names.append(file_name)
os.rename(files[i], os.path.join('/tmp/', '/tmp/valid', file_name))valid_df = pd.DataFrame(valid_dict.values())
## uncomment the below given line to check the head of the dataframe
# valid_df.head()valid_df.index = valid_file_names
valid_df.columns = ['labels']## uncomment the below given line to check the head of the dataframe
# valid_df.head()
- Same process for the train dataset
train_dict = {}
train_file_names = []
for i in tqdm(shuffle[60780:]):
file_name = files[i].split('/')[-1]
labels = np.array(label_df[label_df.index==file_name])
train_dict[file_name] = labels
train_file_names.append(file_name)
os.rename(files[i], os.path.join('/tmp/', '/tmp/train', file_name))train_df = pd.DataFrame(train_dict.values())
train_df.index = train_file_names
train_df.columns = ['labels']## uncomment the below given line to check the head of the dataframe
# train_df.head()
2.3. Custom Batch Generator
import torchvisionfrom glob import globimport osimport matplotlib.pyplot as pltfrom torchvision import transformsfrom torchvision import modelsimport torchfrom torch.autograd import Variableimport torch.nn as nnfrom torch.optim import lr_schedulerfrom torch import optimfrom torchvision.utils import make_gridimport timefrom torch.utils.data import Dataset%matplotlib inline
Here, we have 40 different labels to classify into and hence we need a custom dataloader to load all the 40 labels related to a given images to a numpy array
class MultiClassCelebA(Dataset):def __init__(self, dataframe, folder_dir, transform = None):self.dataframe = dataframeself.folder_dir = folder_dirself.transform = transformself.file_names = dataframe.indexself.labels = dataframe.labels.values.tolist()def __len__(self):return len(self.dataframe)def __getitem__(self, index):image = Image.open(os.path.join(self.folder_dir, self.file_names[index]))label = self.labels[index][0]sample = {'image': image, 'label': label.astype(float)}if self.transform:image = self.transform(sample['image'])sample = {'image': image, 'label': label.astype(float)}return sample
2.4. Generate Batches for Training
tfms = transforms.Compose([transforms.Resize((256, 256)),
transforms.ToTensor()])train_dl = MultiClassCelebA(train_df, '/tmp/train/', transform = tfms)
valid_dl = MultiClassCelebA(valid_df, '/tmp/valid/', transform = tfms)
## check the images
plt.imshow(torchvision.utils.make_grid(train_dl[1]['image']).permute(1, 2, 0))## check the labels related to the given image
(train_dl[1]['label'].astype(float))train_dataloader = torch.utils.data.DataLoader(train_dl, shuffle = False, batch_size = 16, num_workers = 3)
valid_dataloader = torch.utils.data.DataLoader(valid_dl, shuffle = True, batch_size = 16, num_workers = 3)
2.5. Custom Model Architecture
class MultiClassifier(nn.Module):def __init__(self):super(MultiClassifier, self).__init__()self.ConvLayer1 = nn.Sequential(nn.Conv2d(3, 64, 3), # 3, 256, 256nn.MaxPool2d(2), # op: 16, 127, 127nn.ReLU(), # op: 64, 127, 127)self.ConvLayer2 = nn.Sequential(nn.Conv2d(64, 128, 3), # 64, 127, 127nn.MaxPool2d(2), #op: 128, 63, 63nn.ReLU() # op: 128, 63, 63)self.ConvLayer3 = nn.Sequential(nn.Conv2d(128, 256, 3), # 128, 63, 63nn.MaxPool2d(2), #op: 256, 30, 30nn.ReLU() #op: 256, 30, 30)self.ConvLayer4 = nn.Sequential(nn.Conv2d(256, 512, 3), # 256, 30, 30nn.MaxPool2d(2), #op: 512, 14, 14nn.ReLU(), #op: 512, 14, 14nn.Dropout(0.2))self.Linear1 = nn.Linear(512 * 14 * 14, 1024)self.Linear2 = nn.Linear(1024, 256)self.Linear3 = nn.Linear(256, 40)def forward(self, x):x = self.ConvLayer1(x)x = self.ConvLayer2(x)x = self.ConvLayer3(x)x = self.ConvLayer4(x)x = x.view(x.size(0), -1)x = self.Linear1(x)x = self.Linear2(x)x = self.Linear3(x)return F.sigmoid(x)
2.6. How to calculate the accuracy of a Multi-Label classification model?
There are many ways to calculate the accuracy of a multi-label classifier based on the type of image data you are dealing with. You can check this answer on stackexchange to learn more about metrics for evaluation multi-label classifier.
Here, we will be evaluating our model based on how many correct labels our model in able to predict and summing the number of correct label predictions for every image to and then dividing it by the number of labels.
def pred_acc(original, predicted):return torch.round(predicted).eq(original).sum().numpy()/len(original)
2.7. Let’s train and validate our model
from pprint import pprintcriterion = nn.BCELoss()optimizer = optim.SGD(model.parameters(), lr = 0.01, momentum = 0.9, weight_decay = 1e-5)def fit_model(epochs, model, dataloader, phase = 'training', volatile = False):
pprint("Epoch: {}".format(epochs))
if phase == 'training':
model.train()
if phase == 'validataion':
model.eval()
volatile = True
running_loss = []
running_acc = []
b = 0
for i, data in enumerate(dataloader):
inputs, target = data['image'].cuda(), data['label'].float().cuda()
inputs, target = Variable(inputs), Variable(target)
if phase == 'training':
optimizer.zero_grad()
ops = model(inputs)acc_ = []
for i, d in enumerate(ops, 0):acc = pred_acc(torch.Tensor.cpu(target[i]), torch.Tensor.cpu(d))acc_.append(acc)loss = criterion(ops, target)
running_loss.append(loss.item())
running_acc.append(np.asarray(acc_).mean())
b += 1
if phase == 'training':
loss.backward()
optimizer.step()
total_batch_loss = np.asarray(running_loss).mean()
total_batch_acc = np.asarray(running_acc).mean()
pprint("{} loss is {} ".format(phase,total_batch_loss))
pprint("{} accuracy is {} ".format(phase, total_batch_acc))
return total_batch_loss, total_batch_accdef check_cuda():
_cuda = False
if torch.cuda.is_available():
_cuda = True
return _cuda
is_cuda = check_cuda()model = MultiClassifier()
if is_cuda:
model.cuda()
There are 200k images in total in the dataset and using Colab it takes too much of time to train them an if you keep all the model to train on all the images for a large number of epochs there are chances the instance can can disconnected and you might lose your progress so its advisable to use shorter number of epoch and again saved the trained model to your drive and load it again and train for some shorter number of epochs and save it and repeat the process.
trn_losses = []; trn_acc = []val_losses = []; val_acc = []for i in tqdm(range(1, 5)):trn_l, trn_a = fit_model(i, model, train_dataloader)val_l, val_a = fit_model(i, model, valid_dataloader, phase = 'validation')trn_losses.append(trn_l); trn_acc.append(trn_a)val_losses.append(val_l); val_acc.append(val_a)torch.save(model, "drive/My Drive/Model_5_total_EPCHS_Whole_Dataset")
- Train-Save-Load-Repeat
model = MultiClassifier()model = torch.load('drive/My Drive/Model_5_total_EPCHS_Whole_Dataset')if is_cuda:model.cuda()trn_losses = []; trn_acc = []val_losses = []; val_acc = []for i in tqdm(range(1, 5)):trn_l, trn_a = fit_model(i, model, train_dataloader)val_l, val_a = fit_model(i, model, valid_dataloader, phase = 'validation')trn_losses.append(trn_l); trn_acc.append(trn_a)val_losses.append(val_l); val_acc.append(val_a)torch.save(model, "drive/My Drive/Model_10_total_EPCHS_Whole_Dataset")
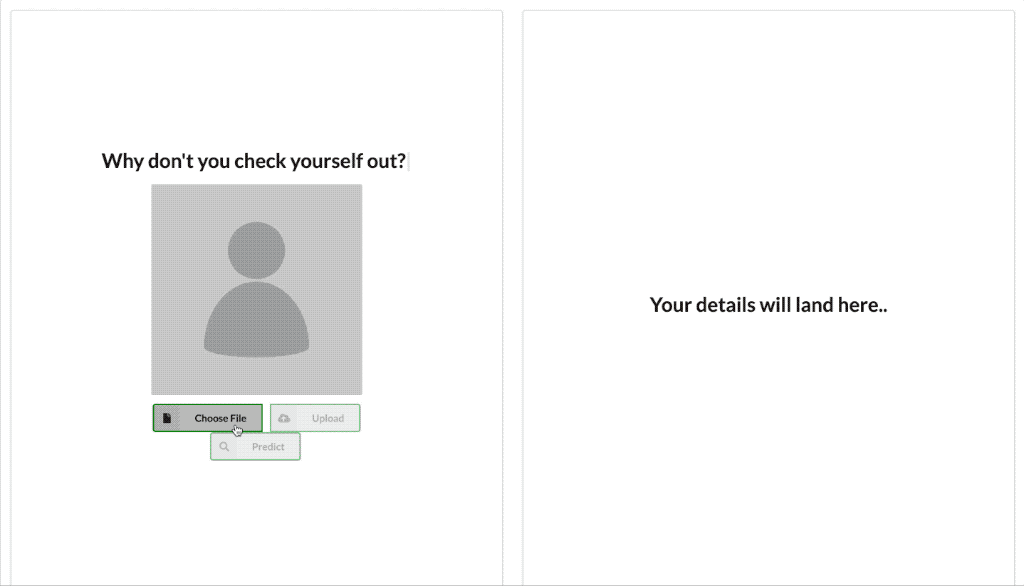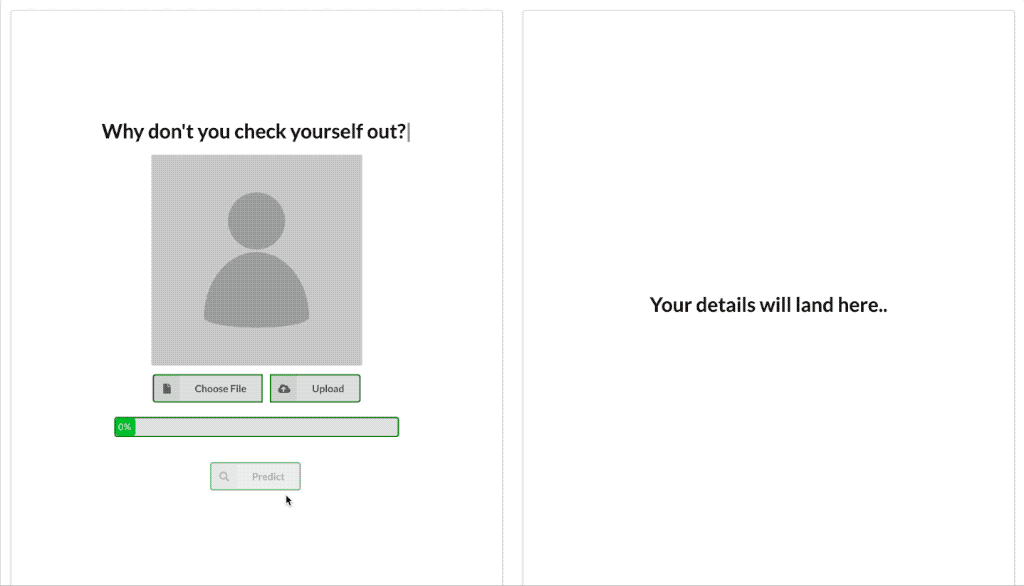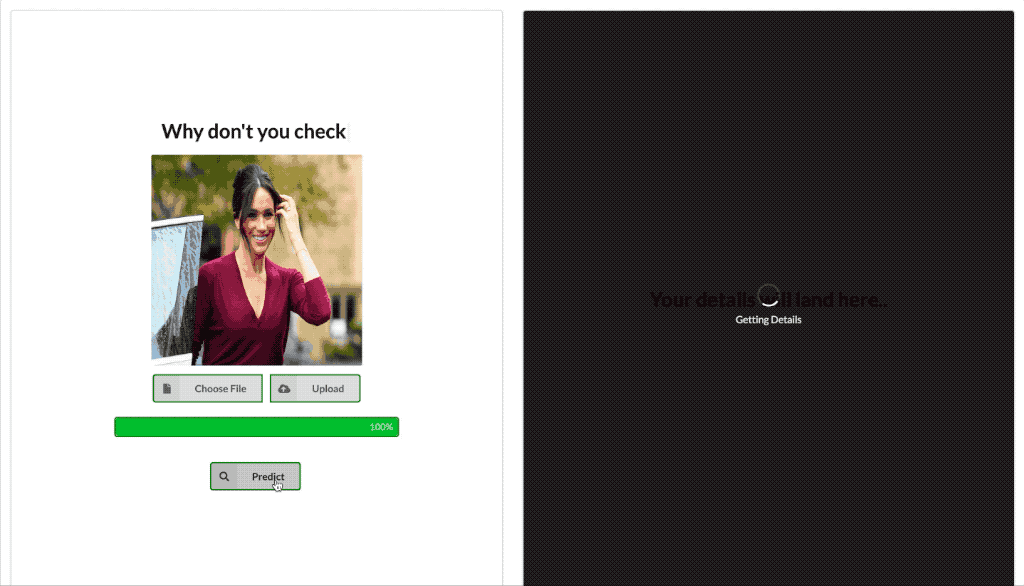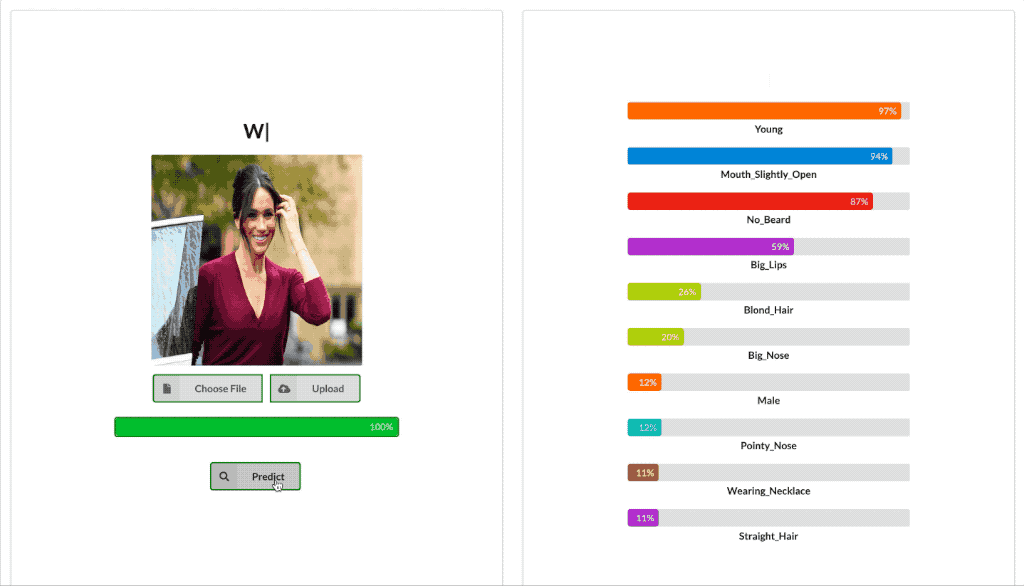
2.8. Predicting Labels of a single image
def predict(img, label_lst, model):tnsr = get_tensor(img)op = model(tnsr)op_b = torch.round(op)op_b_np = torch.Tensor.cpu(op_b).detach().numpy()preds = np.where(op_b_np == 1)[1]sigs_op = torch.Tensor.cpu(torch.round((op)*100)).detach().numpy()[0]o_p = np.argsort(torch.Tensor.cpu(op).detach().numpy())[0][::-1]label = []for i in preds:label.append(label_lst[i])arg_s = {}for i in o_p:arg_s[label_lst[int(i)]] = sigs_op[int(i)]return label, list(arg_s.items())[:10]
Here, we can use the above function to predict the accurately predicted labels and also the top 10 labels in a descending order of their probability.
labels = ['5_o_Clock_Shadow','Arched_Eyebrows','Attractive','Bags_Under_Eyes','Bald','Bangs','Big_Lips','Big_Nose','Black_Hair','Blond_Hair', 'Blurry','Brown_Hair','Bushy_Eyebrows','Chubby','Double_Chin','Eyeglasses','Goatee','Gray_Hair','Heavy_Makeup','High_Cheekbones','Male','Mouth_Slightly_Open','Mustache','Narrow_Eyes','No_Beard','Oval_Face','Pale_Skin','Pointy_Nose','Receding_Hairline','Rosy_Cheeks','Sideburns','Smiling','Straight_Hair','Wavy_Hair','Wearing_Earrings','Wearing_Hat','Wearing_Lipstick','Wearing_Necklace','Wearing_Necktie','Young']def get_tensor(img):tfms = transforms.Compose([transforms.Resize((256, 256)),transforms.ToTensor()])return tfms(Image.open(img)).unsqueeze(0)model_path = '/content/drive/My Drive/Model_40_total_EPCHS_Whole_Dataset'model = torch.load(model_path, map_location=torch.device('cpu'))model = model.eval()predict('/content/cs.jpeg', labels, model)
3. What’s Next?
I have planned to take this model to production using Flask, ReactJS, and Firebase storage. The final output will look something like the following if I don’t end up tweaking it more. The blogs will be published in the following order,
→ Developing the Flask API
→ Web application using ReactJS and Firebase storage
Furthermore, I am planning to extend it to a React Native application and serving the web application and native application using an EC2 instance if people find this series of blogs useful.
If this article helped you in any which way possible and you liked it, please appreciate it by sharing it in among your community. If there are any mistakes feel free to point those out by commenting down below.
To know more about me please click here and if you find something interesting just shoot me a mail and we could have a chat over a cup of ☕️. For updated contents of this blog, you can visit https://blogs.vatsal.ml
Support this content 😃 😇

I have always believed in the fact that knowledge must be shared without thinking about any rewards, the more you share the more you learn. Writing a blog tutorial takes a lot of time in background research work, organizing the content, and showing proper steps to follow. The deep learning blog tutorials require a GPU server to train the models on and they quite cost a bomb because all the models are trained overnight. I will be posting all the content for free like always but if you like the content and the hands-on coding approach of every blog you can support me at https://www.buymeacoffee.com/vatsalsaglani, ☕.
Thanks 🙏
References:
This blog post has inspired me to start blogging.
